News•May 28, 2026
Bio-IT 2026 Signals the Shift from AI Experimentation to Scientific Operating Systems
Brigitte GanterGTM & Product Strategy
The industry’s bottleneck is no longer data generation. It’s scientific reasoning, context, and operational intelligence.
After attending Bio-IT World Conference & Expo 2026 this year, it is clear that the industry has moved past the initial excitement surrounding AI. The conversations have shifted from whether AI can generate hypotheses, summarize literature, analyze omics data, or accelerate workflows. Those capabilities are increasingly assumed. Instead, discussions have shifted to more complex challenges:
“How do we effectively operationalize AI within real-world drug discovery environments?”
While the previous challenges in pharma and biotech were generating sufficient data, organizations are now overwhelmed by it; whether it is genomics, imaging, proteomics, cryo-EM, spatial biology, assay outputs, clinical datasets, real-world evidence, manufacturing signals, and increasingly massive multimodal AI-generated outputs. Despite this abundance of information, scientists struggle with moving from data to confident, timely decision-making.
Bio-IT 2026 made it clear that the industry’s bottleneck is no longer compute power or model capability. Instead, the bottlenecks are now infrastructure, context, interoperability, and trust.
From Sessions to Signal: The Themes That Kept Repeating
A consistent theme emerged across nearly every track of the conference. Sessions on federated learning, AI-native data platforms, FAIR architectures, cloud-native discovery systems, agentic AI, scientific workbenches, and knowledge-driven platforms all pointed toward the same reality: modern drug discovery is becoming an intelligence orchestration problem.
The industry is realizing that building successful AI-driven R&D organizations requires more than simply deploying models. Rather, it requires systems capable of connecting fragmented scientific environments into coherent reasoning ecosystems. Again and again, speakers highlighted familiar operational pain points we’ve heard in years past, including scientific data trapped across disconnected systems, unscalable workflows, institutional knowledge not shared across teams, inconsistent metadata, poor lineage tracking, and AI pilots that fail to reach production. There is a growing recognition that AI without context is merely automation layered on top of chaos.
Consequently, the following topics received significant attention this year:
- Knowledge graphs
- Ontology systems
- Metadata automation
- Federated architectures
- Data products
- Semantic infrastructure
- Multi-modal data analysis
Conversations have shifted from flashy AI demos toward the foundational work required to make AI scientifically useful, reproducible, and trusted. Some of the most interesting discussions came from organizations rethinking the scientist’s experience itself.
Several sessions explored the concept of AI-native scientific workbenches, such as environments where AI acts as an active collaborator embedded directly into the discovery workflow rather than a passive assistant. The vision presented across many talks was not simply “AI tools,” but rather AI teammates or co-scientists. These systems are capable of guiding scientists through data interpretation, workflow orchestration, hypothesis prioritization, reproducibility management, and decision-making.
The distinction is critical. For years, life sciences software has focused on helping scientists manage complexity. However, this emerging generation of platforms aims to help scientists reason through complexity, representing a fundamentally different paradigm.
Discussions on federated learning, particularly involving structural biology and the OpenFold3 initiatives, highlighted a shift in how pharma companies view the balance between competitive advantage and collective progress. While proprietary data silos were once protected as strategic assets, there is a growing recognition that no single company can independently generate enough high-quality multimodal data to fully unlock AI-driven discovery. Federated learning frameworks offer a path forward, allowing for collaborative model deployment while maintaining strict data privacy and IP protection. The concept of collective intelligence without centralized data exposure may become a defining architectural principle for drug discovery over the next decade.
And perhaps most importantly, Bio-IT 2026 demonstrated that the industry is maturing in its approach to AI adoption, with a noticeably shift from hype toward realism.
Speakers openly discussed several major themes and challenges, including:
- Governance challenges
- Infrastructure bottlenecks
- Workflow failures
- Validation requirements
- Operational friction
- Regulatory complexity
- Organizational readiness
The conversation has clearly moved from experimentation to production, from prototypes to scalable systems, and from isolated AI use cases to enterprise scientific operating models.
Bio-IT World 2026: The industry's bottleneck is no longer data; it's reasoning.
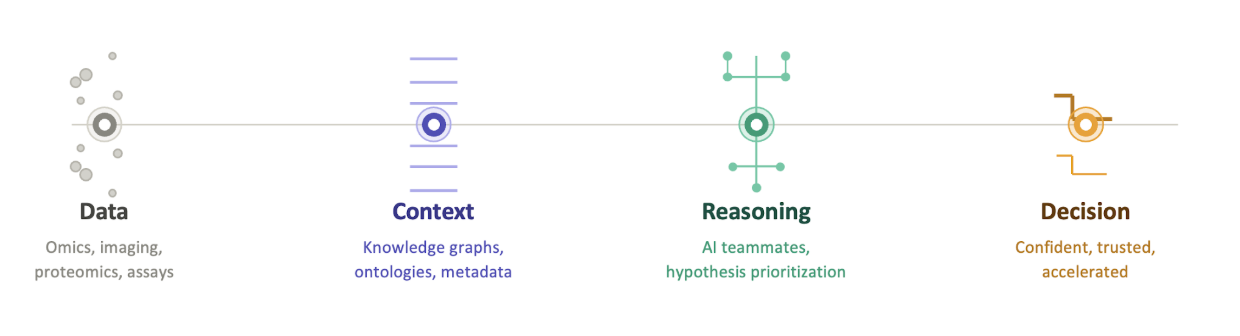
The Next Chapter Belongs to Reasoning Infrastructure
That maturity is healthy for the field, as future pharma and biotech winners will not be defined by the size of the models or GPU clusters alone. Instead, success will belong to organizations that build robust reasoning infrastructure around their science. This requires platforms capable of integrating multimodal data, preserving institutional context, enabling trusted collaboration, and accelerating high-confidence decisions across the discovery lifecycle.
This is precisely why Bio-IT 2026 felt so aligned with the direction Mithrl is driving. Many of the conference’s central themes mirror the challenges we focus on every day: context-aware scientific reasoning, multimodal intelligence, AI-native discovery workflows, reusable scientific memory, and trusted decision acceleration across complex R&D environments. And increasingly, that means not just hypothesis prioritization, but hypothesis generation and moving AI from a filter on existing ideas to an active engine of new ones.
In conversations around Eos, Mithrl’s Scientific Decision Engine, one theme came through consistently: trustworthiness of output is everything. Scientists and R&D organizations are not looking for AI that is merely fast or impressive. They are looking for AI that they can stand behind. That is why Mithrl has invested deeply in transparency, auditability, and reproducibility as foundational design principles. Regardless of what AI or agentic AI is doing for a scientist, if it cannot be trusted, it is not adding value.
The industry narrative is clearly shifting from isolated AI copilots toward intelligent scientific operating systems capable of orchestrating discovery processes. This transition no longer feels theoretical. It is becoming the mainstream standard for life sciences R&D, and it is great to see the field moving in that direction.
Scanning through Bio-IT 2026 posts across LinkedIn, X/Twitter, and Reuters, several recurring themes and quotable lines emerged that resonated with me:
- “AI is moving from tool to teammate.” – appeared repeatedly across conference materials and LinkedIn discussions, signaling a shift toward human-AI collaborative discovery.
- “The real bottleneck is no longer data or compute; it is the scientist’s user experience.” - this was probably one of the defining ideas of the conference. Multiple sessions reframed the problem from “how do we generate more data?” to “how do scientists actually work effectively with AI systems?”
- “The field is moving from prediction systems to decision-orchestration platforms.” where “AI-ready infrastructure” and “data governance” matter more than model novelty.
- “Context-aware scientific intelligence” – scientific context and reasoning are becoming more critical than raw data volume.
- “Real-World Application” - foundation models and multimodal AI are successfully transforming drug discovery from research to practical, regulated use.
We leave Bio-IT 2026 energized by the conversations and inspired by the realism emerging across the field. We are more convinced than ever that the next era of drug discovery belongs to organizations capable of transforming fragmented data into connected scientific intelligence. One of the strongest impressions was that the industry is finally designing systems that allow scientists, data, and AI to reason together more effectively. While challenges regarding trust, infrastructure, governance, interoperability, and validation remain, the direction of the field is clearer than ever.
The AI era of drug discovery has arrived, and the industry is now learning how to truly build around it.
Related articles
News06.22.26
The Conversation Is Shifting at BIO 2026 News05.26.26
Reflections on the Future of Cell and Gene Therapy from Boston News05.18.26
Precision Oncology Is Rich in Data but Poor in Insight. Will AI Finally Bridge the Gap? News05.12.26
Bioinformatics is at a Crossroads: From Data Explosion to Clinical Impact and a Need for Insight Generation